
How well will OpenAI's o1 (not o1-preview) do on the ARC prize when it's released if tested?

Premium
8
Ṁ1989Jan 1
33.76
expected
1D
1W
1M
ALL
The creators of the ARC prize already tested OpenAI's new o1-preview and o1-mini models on the prize. The non-preview version of o1 performed substantially better (see below) on OpenAI's math benchmarks and will seemingly be released before EOY. Assuming it's tested on the ARC prize, how well will the full version of o1 perform?
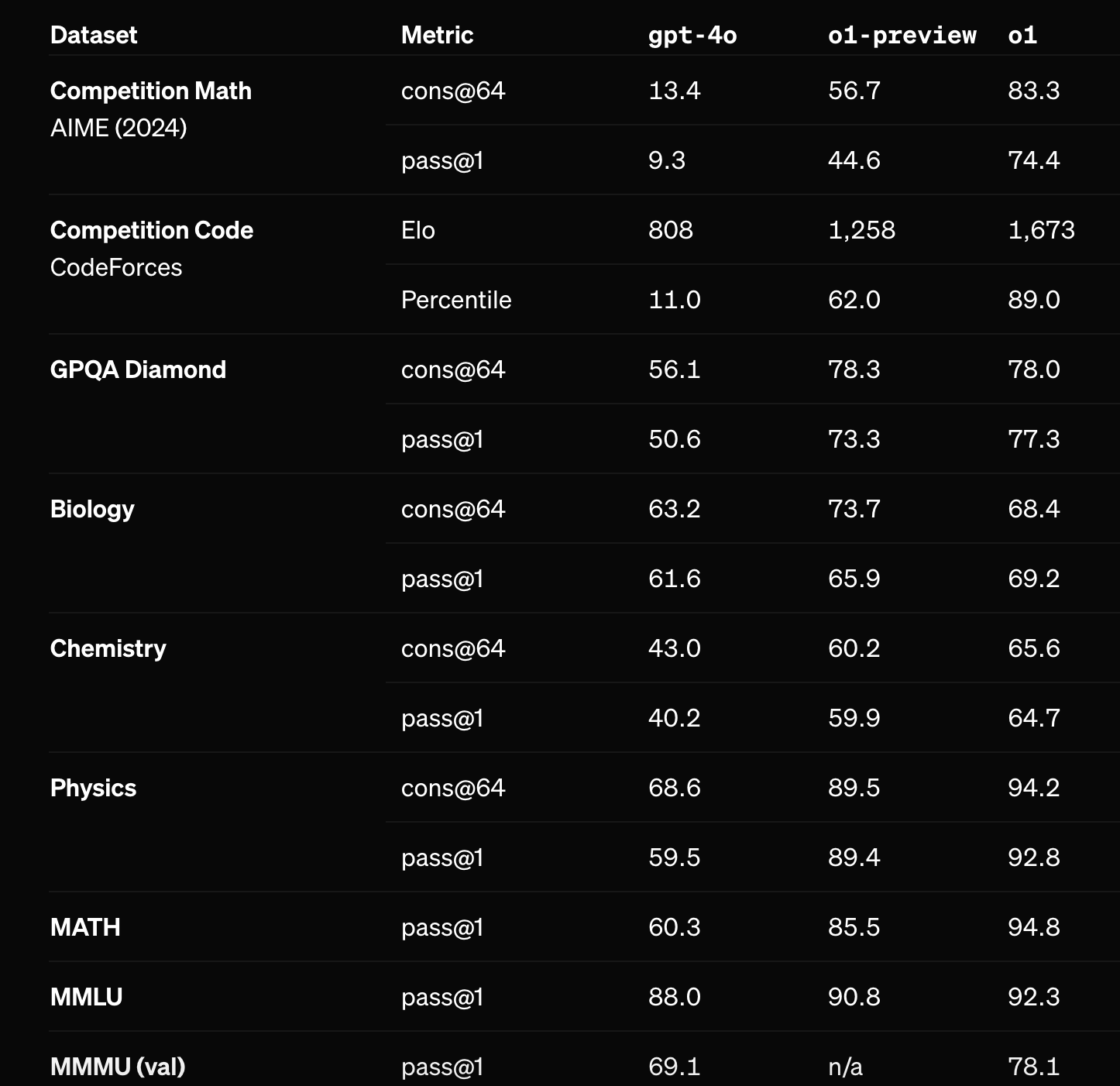
Note 1: I usually don't participate in my own markets, but in this case I am participating since the resolution criteria are especially clear.
Note 2: The ideal case is if the ARC prize tests o1 in the same conditions. If they don't, I'll try to make a fair call on whether unofficial testing matches the conditions closely enough to count. If there's uncertainty, I'll err on the side of resolving N/A.
Get 1,000and
1,000and 1.00
1.00
1,0001.00Sort by:
Related questions
Related questions
Will Anthropic, Google, xAI or Meta release a model that thinks before it responds like o1 from OpenAI by EOY 2024?
27% chance
Will anyone be able to get OpenAI’s new model o1 to leak its system message by EOY 2024?
96% chance
Will OpenAI release o2 as part of the 12 days of Christmas?
2% chance
On which day will OpenAI’s AI o1 be available to the public? (exact day)
Will OpenAI o1 (or any direct iteration) get gold on any International Math Olympiad by the end of 2025?
44% chance
Which of these companies will release a model that thinks before it responds like O1 from OpenAI by EOY 2024?
Will openAI have the most accurate LLM across most benchmarks by EOY 2024?
37% chance
Will Anthropic release a model that thinks before it responds like o1 from OpenAI by EOY 2024?
15% chance
Will OpenAI make o1 pro mode available on the API before 2026?
51% chance
Will OpenAI release o2 before 2026?
79% chance