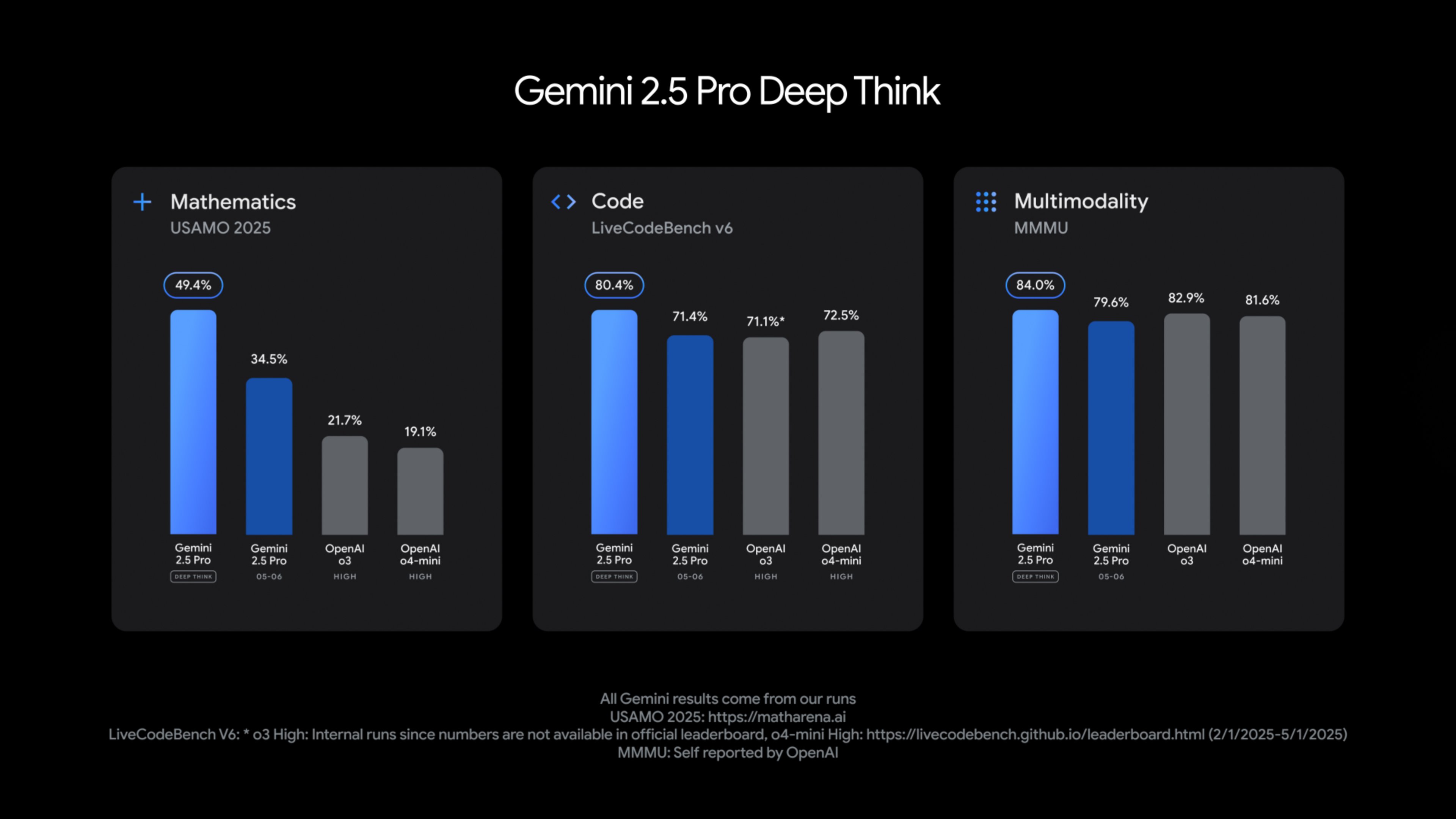
Which of the following will happen during the 2025 Google I/O Developer conference from May 20–21?
Feel free to add your own.
Update 2025-05-22 (PST) (AI summary of creator comment): Regarding the prop bet 'Someone compares Gemini performance to ChatGPT, an OpenAI Model, Claude, an Anthropic Model, Grok, or Perplexity':
The creator indicates that an indirect comparison may be sufficient for a YES resolution.
An indirect comparison could include discussing Gemini's performance on benchmarks or its ranking (e.g., "#1 model for coding"), even if competitor models (ChatGPT, Claude, etc.) are not explicitly named in that specific comparison during the keynotes.
Update 2025-05-22 (PST) (AI summary of creator comment): Regarding a prop bet likely concerning a Gemini Ultra model:
The creator confirms that for resolution purposes, a 'Gemini Ultra subscription' is considered distinct from a 'Gemini Ultra model'.
An announcement of a subscription that provides 'access to the latest bleeding-edge models' (as part of the 'Gemini Ultra subscription perks') may not satisfy a prop bet specifically requiring the announcement or presence of a Gemini Ultra model.
Update 2025-05-22 (PST) (AI summary of creator comment): - The creator has stated that the prop bet 'Gemini Ultra Model Available for Public Use in Some Capacity' will be re-resolved to NO.
 1,000
1,000 1.00
1.00@TotalVerb I waffled back and forth on this. They called one of the Gemini Ultra subscription perks "access to the latest bleeding-edge models", but I suppose you're right.
@mods Could you please re-resolve Gemini Ultra Model Available for Public Use in Some Capacity to NO?
@traders Does anyone have any opinions about how to resolve Someone compares Gemini performance to ChatGPT, an OpenAI Model, Claude, an Anthropic Model, Grok, or Perplexity? They talked about Gemini performance on LMArena and other benchmarks, saying things like "this is the #1 model for coding", but nowhere in the transcript of the main keynote or developer keynote were there any comparison to ChatGPT, an OpenAI Model, Claude, an Anthropic Model, Grok, or Perplexity specifically. I'm leaning towards resolving YES, since they talked about benchmarks and comparisons a lot, just indirectly.