

Davidad, Programme Director at the UK's Advanced Research Invention Agency has publicly stated on his Twitter that he expects LLM 'jailbreaks' to be a solved problem by the end of 2024.
https://x.com/davidad/status/1799261940600254649
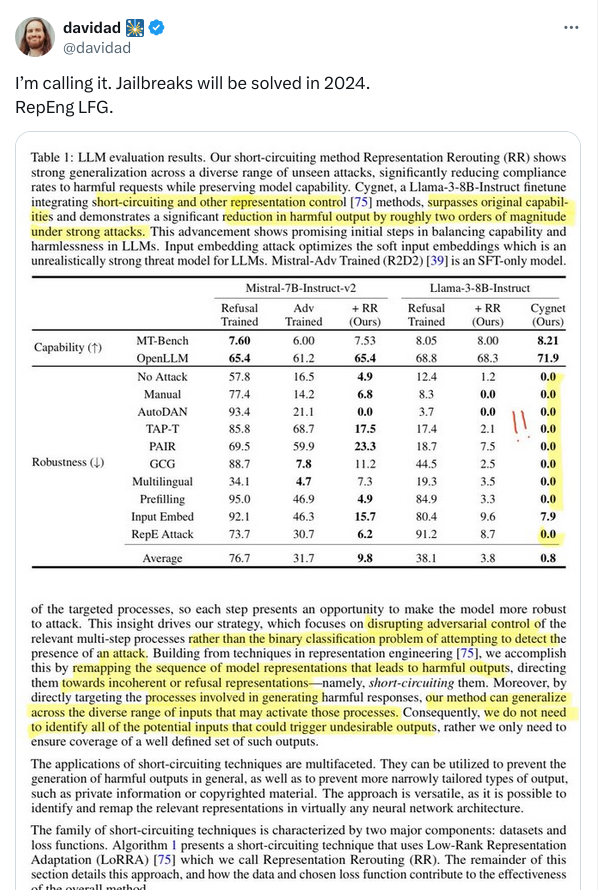
He cites Zou et al's new paper on short circuiting as pushing him over the edge on public willingness to state this: https://arxiv.org/abs/2406.04313
However even if jailbreaks are solved in principle this year, I am skeptical AI companies will immediately deploy them due to the relative nondamage of current model glitches and ire drawn by users for overzealous restrictions.
Therefore this market resolves YES if three "Davidad tier epistemic figures" (in my subjective judgment) make public statements that they believe jailbreaks have in fact been solved in principle before the end of this year. Davidad's existing tweet doesn't count because it's a prediction, not a statement of something he believes has already occurred. The public figures should:
Have substantial relevant expertise and follow the literature
Be known for their relatively balanced evaluations of object level events in AI
A list of people whose endorsements I think would qualify:
Myself
Davidad
Quintin Pope
Zvi Mowshowitz
Jan Leike
Jack Clark
Janus (@repligate on Twitter)
Zack M. Davis
Neel Nanda
This list is by no means exclusive however. For the purposes of this question "solved" means something like Davidad's definition of (paraphrased) "would give reasonable certainty you could put a model with dangerous capabilities behind an API and reliably expect those capabilities not to be elicited by users".
 1,000
1,000 1.00
1.00In principle, companies with APIs could choose to preemptively ban any user that tries to jailbreak their models. I can imagine that such measures could give reasonable certainty that certain capabilities won’t be actually elicited in practice, even though they would be able to be elicited in the absence of that moderation. Not sure if that honors the spirit of the market question or not.
@CharlesFoster In "AI safety" circles this kind of solution is usually rejected on the basis that even one working "jailbreak" context could give an attacker anomalous superintelligent information that destroys everything.
So being able to massively lower the rate at which 'jailbreaks' happen by orders of magnitude is also important.
I'm not remotely a fan of this threat model but since it's mostly the threat model in which 'jailbreaks' matter I think it's reasonable to judge a proposed technique against this backdrop.
There's also the basic case of adversarial examples in agentic systems, where I personally tend to favor a "get away, stop interacting with people who are trying to screw you" approach. But this also relies on being able to scramble up the seeds and lower the base rate of successful attacks by a lot so that it's not reasonable to expect adversarial examples to work.
@CharlesFoster See here for a detailed proposal: https://redwoodresearch.substack.com/p/managing-catastrophic-misuse-without
Though note that this plausibly requires non-trivial KYC to work.

This all suggests single-turn robustness is looking promising, which leaves getting multi-turn robustness by the year's end.
https://x.com/DanHendrycks/status/1832653587555742199
"Three models remain unbroken in the Gray Swan jailbreaking competition (~500 registrants), which is still ongoing. These models are based on Circuit Breakers + other RepE techniques."
@DanHendrycks cygnet models also refuse to respond to innocuous requests like step by step instructions to grow roses: https://x.com/AITechnoPagan/status/1833239052671410315/photo/1
The jailbreak leaderboard really should include a helpfulness score as well.
@AdamKarvonen I do think we should probably clarify that “solving jailbreaks” by making a model generally unhelpful or useless does not match the spirit of this market’s question.
@CharlesFoster Yes. The model must be usable in the way people would expect from something like ChatGPT. It must be something a lab would be willing to deploy.
The person who "jailbroke Cygnet in <24 hours after its release" in fact had early access to the model for weeks.
I don't prove prescience through this mechanism. I also notice people similar to me get addicted to things like this. Criticisms here:
https://arxiv.org/pdf/2206.15474#page=20
More interested in intellectual energies on tail upside value than probability refinement. Whether I spend my time on productive things that can have some tail upside impact is a more substantial bet/better way to keep score than mana.
A list of people whose endorsements I think would qualify:
Myself
Davidad
Quintin Pope
Zvi Mowshowitz
Jan Leike
Jack Clark
Janus (@repligate on Twitter)
Zack M. Davis
Neel Nanda
This list is by no means exclusive however.
Noting the open-endedness of this list, and that both the market creator (“myself”) and Davidad are YES holders.
@CharlesFoster Yes this is clearly a subjective market, you either trust me to be realistic about this or not. I would much rather say I was totally wrong than cheat you (and be publicly seen to cheat you no less) out of manabux.
@JohnDavidPressman Understood. You and others can interpret my continued NO holdings on this market as evidence of my trust that y’all will resolve this fairly.
@CharlesFoster Yeah, I mean you can invert the question like "Would JDP be willing to tweet that he thinks jailbreaks are solved when he doesn't actually think that under his real name in exchange for 25 cents/5 bucks/whatever?"
My personal expectation is that if I mark this one yes it's at least 50/50 that I will not be one of the names on the 'expert' list. I would only want to use myself if no one else is available and I really do think on reflection that jailbreaks are solved in a way I'm excited to tell everyone about.
@JohnDavidPressman In general if jailbreaks are solved in principle this should be something there is relatively broad consensus about. It shouldn't be a thing where I need to nickel and dime it by picking the exact 3 people who happen to think this thing for idiosyncratic reasons and if I find myself doing that it's a forecasting smell.
@JohnDavidPressman How about this, if I resolve YES on this question and my endorsement is used it needs to be an actual full blog post explaining why I think this. You can all then dunk on me in the Gary Marcus future that follows if I'm wrong for being a Big Language Model Research stooge.