

Richard Ngo predicted on Twitter that, before 2026, LLMs (or whatever SOTA large models are at the time) will be able to beat any human on any computer task a typical white-collar worker can do in 10 minutes.
In this question, I will attempt to grade whether this prediction is true based on my best subjective judgement in Jan 2026, by asking people to come up with counterexamples that I then evaluate.
For the purposes of this question, all Manifold users will be considered by default to be "typical white-collar workers" unless it is clear to me that the Manifold user in particular has some sort of very unusual skill that I wouldn't expect >10% of Manifold users to have.
I will rely on my subjective judgement to evaluate the credibility of cases. In the case this question is to resolve, I will allow 48 hours of discussion before resolving.
I will not personally be trading on this market because it relies on my subjective judgement.
Note that this prediction will likely only resolve based on publicly available large models, so it's possible that it may resolve NO even if Ngo was techinically right.
 1,000
1,000 1.00
1.00Does this include tasks which involve navigating to future-captcha-locked or otherwise bot-avoidant websites?
A set of 4-15 minute tasks (selected for other purposes) have 50% completion rate on 4o/Claude3.5. That's average case, and this question measures worst-case performance. Community seems too high here I'm at ~15% on this.
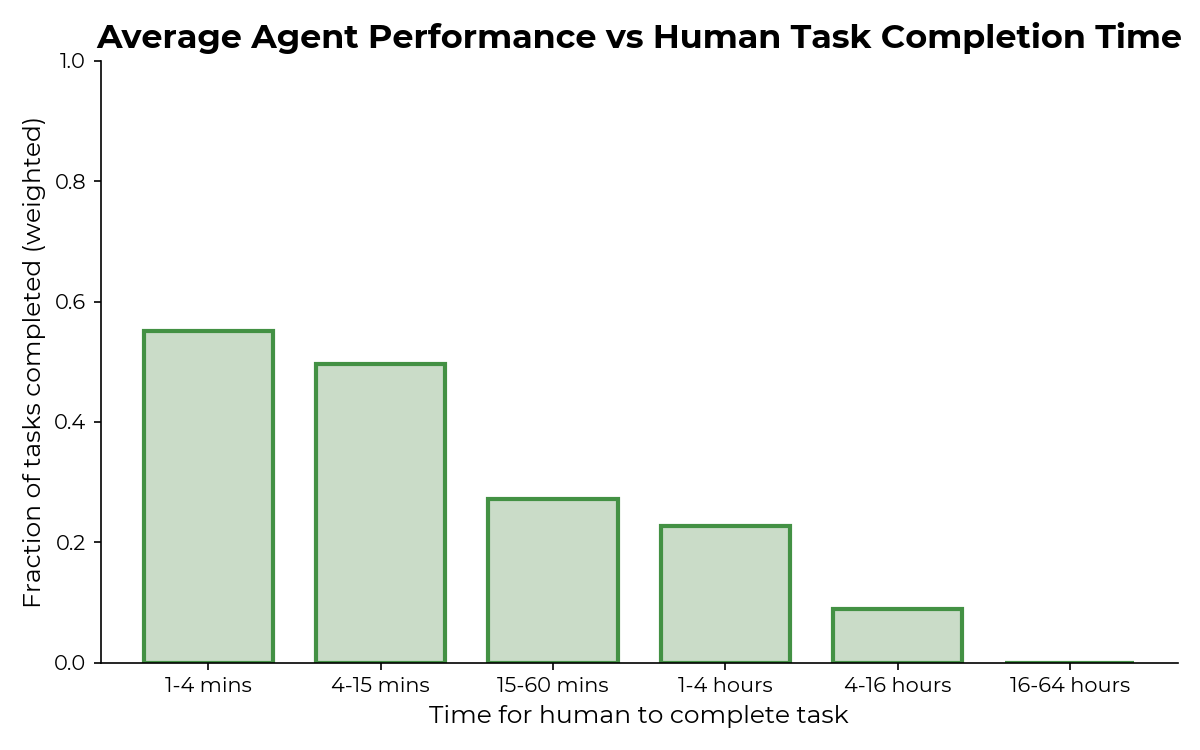
https://metr.org/blog/2024-08-06-update-on-evaluations/
Similarly:
Today e.g. I implemented an auto save in some column filters that we have on a table. It took probably around 5-10 minutes.
No current LLM could have done that given the specific knowledge of the codebase that would have been (i.e. I am also claiming that GPT-4 with plugins + uploading code could not have done it alone.)
Given that I am right about my claim, would this count for your test, or is it based on the assumption that it is an easy task that will not require any knowledge of unique circumstances?
The definition of "computer task" is doing a lot of work here. How do you delineate? Is it "anything that you can achieve without moving away from computer" or rather "task that does not interact with anything outside your computer" or something else?
Some examples where definitions might conflict:
1) use e-mails to schedule a meeting with A,B and C
2) find datasets of age-based mortality in Cambodia
3) make a video call with my boss pretending I am still in my office
@MartinModrak Another aspect: how much prompt engineering do you allow per task? Should I be able to use basically the same instructions I would give to a human? Or is spending couple man-months on prompt engineering allowed for each family of tasks akin to:
@MartinModrak I think 1 + 2 of yours should count but not 3. Maybe anything you can achieve without moving away from your computer that doesn't involve faking a human identity.
@Mira What kind of tasks are you hiring for? I still would have a strong preference for the average Manifolder.